SQL入门基础
SQL #入门2012-05-02 09:03
基本知识点:
SQL常用字段类型:bit(可选值0、1)、datetime、int、varchar、nvarchar(可能含有中文等ASCII码之外的字符用nvarchar)。Nvarchar(50)、Nvarchar(MAX) varchar、nvarchar 和char(n)的区别: char(n)不足长度n的部分用空格填充。Varchar(n)字符串长度小于n时,其长度为字符本身的长度。Var:Variable,可变的。
SQL语句中字符串用单引号,这一点与C#中不同。
主键就是数据行的唯一标识。不会重复的列才能当主键。主键有两种选用策略:业务主键和逻辑主键。通常使用没有任何业务意义的字段做主键,即逻辑主键。
SQLServer中两种常用的主键数据类型:int(或bigint)+标识列(又称自动增长字段);uniqueidentifier(又称Guid、UUID)SQLServer中生成GUID的函数newid(),.Net中生成Guid的方法:Guid.NewGuid(),返回是Guid类型。
Int自增字段的优点:占用空间小、无需开发人员干预、易读;缺点:效率低;数据导入导出的时候很痛苦。Guid的优点:效率高、数据导入导出方便;缺点占用空间大、不易读。业界主流倾向于使用Guid。
创建表:create table T_Person(Id int not null,Name nvarchar(50),Age int null)删除表:drop table T_Person
数据插入
Insert into T_Person(Name,Age) values(‘Bill’,29)
如果插入的行中有些字段的值不确定,那么Insert的时候不指定那些列即可。
数据更新
1. 更新一部分数据: update T_Person set Age=30 where Name=’Jason’,用where语句表示只更新Name是’Jason’的行,注意SQL中等于判断用单个=,而不是==。
2. Where中还可以使用复杂的逻辑判断: update T_Person set Age=30 where Name=’Jason’ or Age>28,or相当于C#中的||(或者)。
3. update T_Person2 set NickName=N’小五’ where Name=’Jason’ 注意赋值时字符串如果包含中文,则前面加N以确保不会乱码。
4. Where中可以使用的其他逻辑运算符:or、and、not、<、>、>=、<=、!=(或<>)等。
数据删除
删除表中全部数据:delete from T_Person。注意:delete只是删除数据,表还在,和Drop Table不同。
Delete 也可以带where子句来删除一部分数据:delete from T_Person where FAge > 20
数据检索
简单的数据检索 :select * from T_Employee
只检索需要的列 :select FNumber from T_Employee 、select FName,FAge from T_Employee
列别名:select FNumber as 编号,FName as 姓名,FAge as 年龄from T_Employee
使用where检索符合条件的数据:select FName from T_Employee where FSalary<5000。
还可以检索不与任何表关联的数据:select 1+1;select newid();select getdate();
数据汇总
SQL聚合函数:MAX(最大值)、MIN(最小值)、AVG (平均值)、SUM (和)、COUNT(数量)
大于25岁的员工的最高工资 :SELECT MAX(FSalary) FROM T_Employee WHERE FAge>25
最低工资和最高工资:SELECT MIN(FSalary),MAX(FSalary) FROM T_Employee
数据排序
按照年龄升序排序所有员工信息的列表:SELECT * FROM T_Employee ORDER BY FAge ASC
按照年龄从大到小降序排序,如果年龄相同则按照工资从大到小降序排序 :SELECT * FROM T_Employee ORDER BY FAge DESC,FSalary DESC
ORDER BY子句要放到WHERE子句之后 :SELECT * FROM T_Employee WHERE FAge>23 ORDER BY FAge DESC,FSalary DESC
通配符过滤
通配符过滤使用LIKE 。
单字符匹配的通配符为半角下划线“_”,它匹配单个出现的字符。如以任意字符开头,剩余部分为“erry” :SELECT * FROM T_Employee WHERE FName LIKE '_erry'
多字符匹配的通配符为半角百分号“%”,它匹配任意次数(零或多个)出现的任意字符。 “k%”匹配以“k”开头、任意长度的字符串。检索姓名中包含字母“n”的员工信息 :SELECT * FROM T_Employee WHERE FName LIKE '%n%'
空值处理
数据库中,一个列如果没有指定值,那么值就为null,这个null和C#中的null不同,数据库中的null表示“不知道”,而不是表示没有。因此select null+1结果是null因为“不知道”加1的结果还是“不知道”。
SELECT * FROM T_Employee WHERE FNAME=null ; SELECT * FROM T_Employee WHERE FNAME!=null ;都没有任何返回结果,因为数据库也“不知道”。
SQL中使用is null、is not null来进行空值判断: SELECT * FROM T_Employee WHERE FNAME is null ; SELECT * FROM T_Employee WHERE FNAME is not null ;
多值匹配
SELECT FAge,FNumber,FName FROM T_Employee WHERE FAge IN (23,25,28)
范围值:SELECT * FROM T_Employee WHERE FAGE>=23 AND FAGE <=27 ;SELECT * FROM T_Employee WHERE FAGE BETWEEN 23 AND 27
数据分组
按照年龄进行分组统计各个年龄段的人数:SELECT FAge,Count(*) FROM T_Employee GROUP BY Fage
GROUP BY子句必须放到WHERE语句的之后
没有出现在GROUP BY子句中的列是不能放到SELECT语句后的列名列表中的 (聚合函数中除外)
错误:SELECT FAge,FSalary FROM T_Employee GROUP BY FAge
正确:SELECT FAge,AVG(FSalary) FROM T_Employee GROUP BY FAge
Having语句
在Where中不能使用聚合函数,必须使用Having,Having要位于Group By之后, SELECT FAge,COUNT(*) AS 人数 FROM T_Employee GROUP BY FAge HAVING COUNT(*)>1
注意Having中不能使用未参与分组的列,Having不能替代where。作用不一样,Having
是对组进行过滤。
限制结果集行数
select top 5 * from T_Employee order by FSalary Desc
检索按照工资从高到低排序检索从第六名开始一共三个人的信息 :SELECT top 3 * FROM T_Employee WHERE FNumber NOT IN (SELECT TOP 5 FNumber FROM T_Employee ORDER BY FSalary DESC) ORDER BY FSalary DESC
SQLServer2005后增加了Row_Number函数简化实现,参看后面。
去掉数据重复
SELECT FDepartment FROM T_Employee →SELECT DISTINCT FDepartment FROM T_Employee
DISTINCT是对整个结果集进行数据重复处理的,而不是针对每一个列,因此下面的语句并不会只保留Fdepartment进行重复值处理:SELECT DISTINCT FDepartment,FSubCompany FROM T_Employee只有当FDepartment和FSubcompany两列同时重复时才会去掉重复数据。
联合结果集
简单的结果集联合:SELECT FNumber,FName,FAge FROM T_Employee UNION SELECT FIdCardNumber,FName,FAge FROM T_TempEmployee
基本的原则:每个结果集必须有相同的列数;每个结果集的列必须类型相容。
例:SELECT FNumber,FName,FAge,FDepartment FROM T_Employee
UNION SELECT FIdCardNumber,FName,FAge,‘临时工,无部门' FROM T_TempEmployee
3. SELECT FName FROM T_Employee
UNION SELECT FName FROM T_TempEmployee
此句中UNION合并两个查询结果集,并且将其中完全重复的数据行合并为一条
4. SELECT FName FROM T_Employee
UNION ALLSELECT FName FROM T_TempEmployee
Union因为要进行重复值扫描,所以效率低,因此如果不是确定要合并重复行,那么就用UNION ALL
数字函数
ABS() :求绝对值。
CEILING():舍入到最大整数 。3.33将被舍入为4、2.89将被舍入为3、-3.61将被舍入为-3。 Ceiling→天花板
FLOOR():舍入到最小整数。3.33将被舍入为3、2.89将被舍入为2、-3.61将被舍入为-4。 Floor→地板。
ROUND():四舍五入。舍入到“离我半径最近的
数” 。Round→“半径”。Round(3.1425,2)。
字符串函数
LEN() :计算字符串长度
LOWER() 、UPPER () :转小写、大写
LTRIM():字符串左侧的空格去掉,RTRIM () :字符串右侧的空格去掉,LTRIM(RTRIM(' bb '))字符串两侧的空格都去掉
SUBSTRING(string,start_position,length)参数string为主字符串,start_position为子字符串在主字符串中的起始位置,length为子字符串的最大长度。SELECT SUBSTRING('abcdef111',2,3)
日期函数
GETDATE() :取得当前日期时间
DATEADD (datepart , number, date ),计算增加以后的日期。参数date为待计算的日期;参数number为增量;参数datepart为计量单位,可选值如下表:
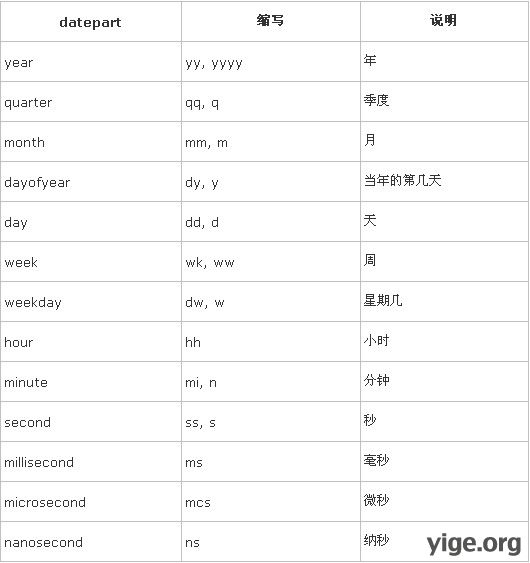
DATEADD(DAY, 3,date)为计算日期date的3天后的日期,
DATEADD(MONTH ,-8,date)为计算日期date的8个月之前的日期
3. DATEDIFF ( datepart , startdate , enddate ) :计算两个日期之间的差额。 datepart 为计量单位,可取值参考DateAdd。
统计不同工龄的员工的个数:
select DateDiff(year,FInDate,getdate()),count(*) from T_Employee
group by DateDiff(year,FInDate,getdate());
4. DATEPART (datepart,date):返回一个日期的特定部分
统计员工的入职年份个数:
select DatePart(year,FInDate),count(*)from T_Employee group by DatePart(year,FInDate)
类型转换函数
CAST ( expression AS data_type)
CONVERT ( data_type, expression)
例1:Select cast(‘123’ as int),
cast(‘2012-12-12’ as datetime),
convert(datatime,’2011-11-11’),
convert(varchar(20),’123’)
例2:SELECT FIdNumber,RIGHT(FIdNumber,3) as 后三位,
CAST(RIGHT(FIdNumber,3) AS INTEGER) as 后三位的整数形式,
CAST(RIGHT(FIdNumber,3) AS INTEGER)+1 as 后三位加1,
CONVERT(INTEGER,RIGHT(FIdNumber,3))/2 as 后三位除以2
FROM T_Person
空值处理函数
ISNULL(expression,value) :如果expression不为空则返回expression,否则返回value。
例:SELECT ISNULL(FName,’佚名’) as 姓名 FROM T_Employee
CASE函数用法1
单值判断,相当于switch case
语法:CASE expression
WHEN value1 THEN returnvalue1
WHEN value2 THEN returnvalue2
WHEN value3 THEN returnvalue3
ELSE defaultreturnvalue
END
例子:
SELECT FName,
(CASE FLevel
WHEN 1 THEN ‘VIP客户’
WHEN 2 THEN ‘高级客户’
WHEN 3 THEN ‘普通客户’
ELSE ‘客户类型错误’
END) as FLevelName
FROM T_Customer
CASE函数用法2
语法:
CASE
WHEN condition1 THEN returnvalue1
WHEN condition2 THEN returnvalue2
WHEN condition3 THEN returnvalue3
ELSE defaultreturnvalue
END
相当于if…else…else….
2. 例子:
SELECT FName, FWeight,
(CASE
WHEN FWeight<40 THEN ‘瘦瘦’
WHEN FWeight>50 THEN ‘肥肥’
ELSE 'ok'
END) as isnormal
FROM T_Person
索引Index
使用索引能提高查询效率,但是索引也是占据空间的,而且添加、更新、删除数据的时候也需要同步更新索引,因此会降低Insert、Update、Delete的速度。只在经常检索的字段上(Where)创建索引。
表连接Join
Join语法:
select o.BillNo,c.Name,c.Age
from T_Orders as o
join T_Customers as c on o.CustomerId=c.Id
inner join(等值连接) 只返回两个表中满足关系(联结字段相等)的行,简写为join
left join(左联接) 返回左表中的所有记录和右表中满足关系的记录
right join(右联接) 返回右表中的所有记录和左表中满足关系的记录
子查询
1. 单值做为子查询:
SELECT 1 AS f1,2,(SELECT MIN(FYearPublished) FROM T_Book),
(SELECT MAX(FYearPublished) FROM T_Book) AS f4
只有返回且仅返回一行、一列数据的子查询才能当成单值子查询。
下面的是错误的:
SELECT 1 AS f1,2,(SELECT FYearPublished FROM T_Book)
2. 如果子查询是多行单列的子查询,这样的子查询的结果集其实是一个集合。
SELECT * FROM T_Reader WHERE FYearOfJoin IN
(
select FYearPublished FROM T_Book
)
3. 限制结果集。返回第3行到第5行的数据( ROW_NUMBER 不能用在where子句中,所以将带行号的执行结果作为子查询,就可以将结果当成表一样用了):
SELECT * FROM
(
SELECT ROW_NUMBER() OVER(ORDER BY FSalary DESC) AS rownum,
FNumber,FName,FSalary,FAge FROM T_Employee
) AS a
WHERE a.rownum>=3 AND a.rownum<=5
相关文章
- SQL Server数据库开发中的十大问题 2012/05/02
- SQL Server 2012新增的内置函数介绍 2012/05/02
- SQL Server存储过程编写和优化的规范 2012/05/02
- Mysql百万级数据库优化方案 2012/04/30
- 减少SQL Server数据库中死锁发生的方法 2012/04/29
- SQL Server用户及权限 2012/04/29